如果有2个数据库如何实现事务一致性?
我最先想到的是双事务方案:
对每个数据库开一个事务,最后两边同时提交,任意一边有一步出错两个同时回滚
但是这个方案有个问题:
最终会连续2次commit,万一第一次commit提交成功,第二次commit提交失败怎么办,最极端的情况就是第一次commit后机器挂了
这种情况虽然不太可能发生,但还是有极微小概率有可能发生。在日积月累无数次执行后,总会有一两条不一致,如果那一两条刚好是大额消费就够呛。
研究了网上分布式事务的实现方案,其实解决方案很简单:
只要将请求的所有信息记录一张请求日志表(消息表),可以单独记录或者在第一次commit的时候记录。
并增加定时任务通过日志表对其他数据进行补偿:如果日志是单独记录的,就要对双库都进行补偿。如果日志跟随第一次commit一起记录,就只需要对第二次commit的表记录进行补偿。
通过双commit+补偿机制,能完美解决问题,二者缺一不可。
通过双commit来保证大部分不走补偿机制的请求的数据一致性。如果没做双commit虽然最终能通过补偿机制保证数据一致性,但在补偿之前任意一张表都有可能出现数据不一致的情况。
通过补偿机制来保证最终的数据一致性,就是做个完美兜底。即使偶尔定时任务挂掉也问题不大,定时任务无限次补偿最终一定能补偿成功。
———————————– 以下是参考的文章 —————————————
(文章通过消息队列的方案来保证多机器一致性,这种方案比较通用。但如果一台机器能同时连接两台数据库,就可以不用整消息队列了)
聊聊分布式事务一致性与本地消息表
我个人比较推崇本地消息表模式来实现最终一致性。首先本地消息表的设计不仅可以解决事务一致性的问题,对于消息队列常见问题中的消息丢失与消息幂等其实都是可以通过本地消息表来解决;其带来的好处是多重的。
什么是分布式事务一致性
大白话就是对数据源进行拆分后,多库多机器的多数据库事务一致性问题。因为此时你的系统可能不是分布式的(当然这不满足分布式的概念),我想表达的是事务的一致性其实就是多机器多库下的数据事务一致性问题。
不管是计算机还是数学行业等,某些问题的解决都是基于理论科学来的,所以我们这行的顶级职称有计算机科学家这类的头衔。分布式事务的解决依赖CAP原则与BASE理论。
CAP
CAP理论描述了分布式系统中的基本原则,其中C是指Consistency(一致性),A是指Availability(可用性)和P是指Partition tolerance(区分容错性)。CAP原则指CAP三者不能同时满足,要么能同时满足CP即同时满足区分容错性和一致性,要么同时满足AP即同时满足区分容错性和可用性。从中可以看出,P是分布式系统的基础,没有区分容错性就谈不上分布式系统了。
CAP只能满足AP或CP的原因是,分布式节点之间通常存在一个数据拷贝的过程,在这一个过程中是只能满足AP或者CP的。举个例子好了,比如redis分布式集群中,当一个写请求打到一个主节点上,几乎同时另一个读请求打到redis这个主节点的对应从节点上,此时请问该从节点能返回刚才写在主节点的数据吗?若要保证CP,此时数据正在从主节点复制到从节点的路上,此时该节点的该数据是不可用的;若要保证AP,因为数据正在从主节点复制到从节点的路上,因此节点间的数据状态是不一致的。
BASE理论
前面讲到分布式系统的CAP原则要么同时满足AP要么同时满足CP,那么BASE理论则是CAP原则权衡的结果。BASE是指Basically Available(基本可用的),Soft state(软状态),Eventual consistency(最终一致性)。
Basically Available是指在分布式集群节点中,若某个节点宕机,或者在数据在节点间复制的过程中,只有部分数据不可用,但不影响整个系统的整体的可用性。
Soft state是指软状态即这个状态只是一个中间状态,允许数据在节点集群间操作过程中存在存在一个时延,这个中间状态最终会转化为最终状态。
Eventual consistency是指数据在分布式集群节点间操作过程中存在时延,与ACID相反,最终一致性不是强一致性,在经过一定时间后,分布式集群节点间的数据拷贝能达到最终一致的状态。
分布式事务一致性
说到分布式事务一致性,就离不开2PC与3PC理论。暂时不展开描述。先说说一致性的类型。
- 强一致性
- 弱一致性
- 最终一致性
强一致性解决方案
基于2PC与3PC实现的XA模式,比如Seata中XA模式的实现
最终一致性
- 本地消息表
- saga
- tcc
- at(seata框架独有)
什么是本地消息表模式
本地消息表方案最初是ebay提出的,其实也是BASE理论的应用,属于可靠消息最终一致性的范畴。其概念图如下:
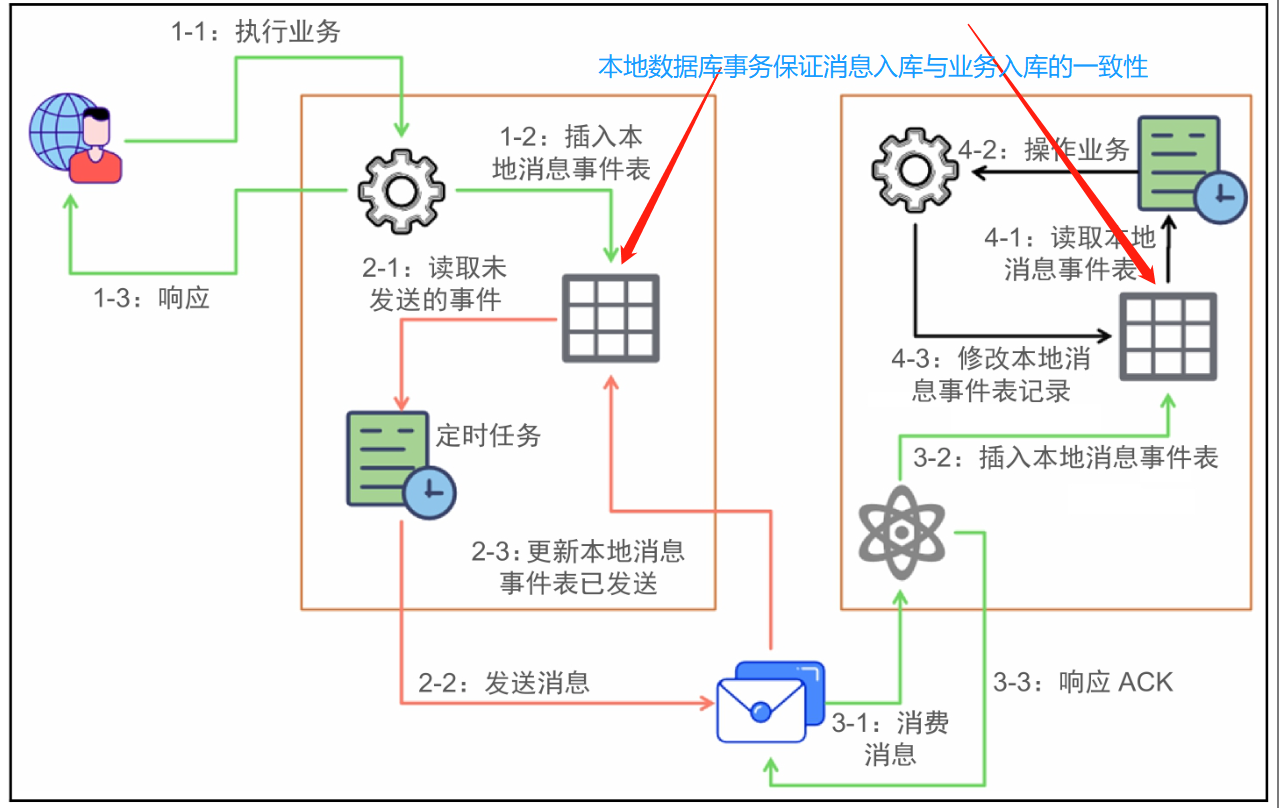
这里是拆分出来了多个本地消息表,看自己的业务。如果规模比较小,可以只创建一个本地消息表。但业务比较大的时候,我个人是推崇这种模式,因为解耦,业务的发起方。只处理新建、已发送状态的消息;业务的消息方,只处理已接收、已处理状态的消息。
具体怎么做呢?消息生产方(也就是发起方),需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方(也就是发起方的依赖方),需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
消息的丢失与幂等
消息队列的引入可以实现业务的异步与解耦,以及流量削峰。尤其是前两者,我在之前的项目中用到了,反正我很爽。但是没有银弹。消息队列的引入会带来一定的问题,其中最常见的就是消息的丢失与幂等!
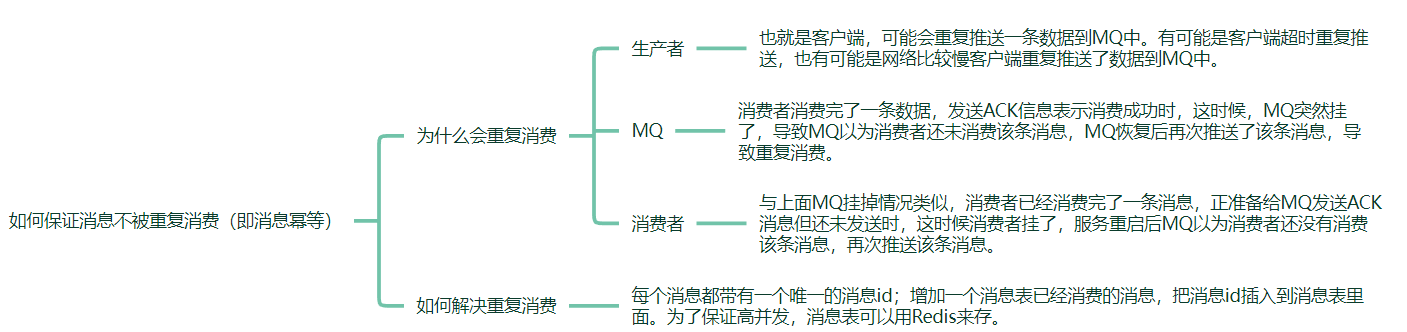
消息幂等
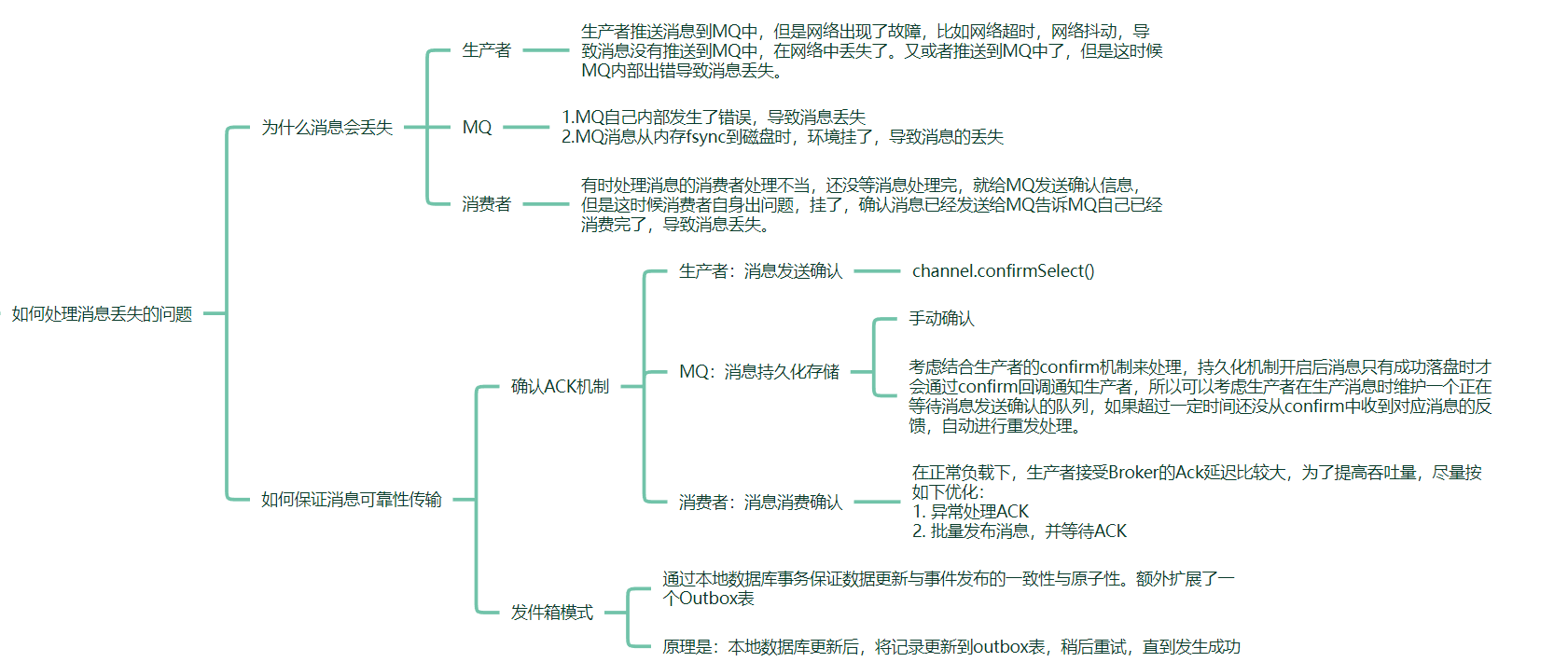
消息丢失
总结
如上,引入一个中间的本地消息表,除了解决事务的一致性外,同样可以解决消息的丢失与幂等性问题,一举多得。而且从业务的健壮性与数据一致性来看,一般都会增加一个补偿机制,我在之前的项目中就强力推行补偿机制。本地消息表模式就是补充机制的最直观方式。

